Before covering what to remember, let’s cover the basics. What is table partitioning in SQL Server? In SQL Server a partitioned table is one that is referred to as one table but is subdivided into multiple partitions in which data is partitioned horizontally. A partitioned table has the following properties:
- Partition Scheme: This defines which file group the partitions’ data will be stored.
- Partition Functions: This defines how the data is partitioned (think of it as a WHERE clause, which segregates data into separate partitions.) This ensures that a group of rows are mapped together into partitions.
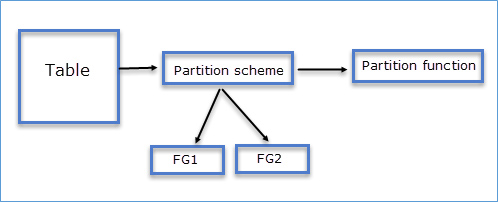
The following is an example of testTable which is partitioned based on tranMonth:
CREATE PARTITION FUNCTION monthRangeFunction (int)
AS RANGE LEFT FOR VALUES (2, 4, 6, 8, 10, 12)
go
CREATE PARTITION SCHEME monthRangeScheme
AS PARTITION monthRangeFunction
TO (FG1, FG2, FG3, FG4, FG5, FG6, FG7)
go
When executing the above query, the data is partitioned based on the values specified for month. Here is an example of how the data is partitioned:
More details about the CREATE PARTITION SCHEME and CREATE PARTITION FUNCTION can be found on Microsoft’s Developer Network site here and here.

Benefits Of Partitioning
- Speed: Data transfer is relatively fast in a partition compared to a table which is not partitioned.
- Query performance: If you have queries which deal with a specific set of data, (e.g. current month) then partitioning the table will improve the performance of these types of queries.
- Easy maintenance: Data in a partition can be easily SWITCHed , SPLIT, MERGEd as explained in these two articles.
- Transferring Data Efficiently by Using Partition Switching
- Alter Partition Function (Transact-SQL)
Also, you can chose to rebuild a partition of an index instead of rebuilding the entire partition.
Things To Remember
So far we’ve shown that partitioning is a great feature; but it does not fix all performance problems. Here are the few things to keep in mind while working with SQL Server partitioning:
As explained above, SWITCHING partitions is an easy approach to transfer data efficiently. But keep in mind:
- The destination table. The partition must be created before SWTICHING the partition and it should be empty.
- The destination and source partitions should reside on the same FILEGROUP.
- If the partition has an identity column there is a possibility that the destination partition may have duplicate values or gaps in the identity column.
- Both the source and destination partitions should have the same clustered and non-clustered indexes.
- During the partition switch, a Schema Modification lock held on the table can cause a block for the users accessing the table.
- An index is said to be aligned if the index and the table on which it is created both use the same partitioning function and columns in the same order. If there a large number of partitions defined, it is recommended to have more memory on the server. Otherwise there is a likelihood that the partitioned index may fail especially in the case of non-aligned indexes.
This is because when building the partition, SQL Server will create a sort table for each partition in the corresponding filegroup or in tempdb if the sort_in_tempdb option is specified. This requires a certain amount of memory. If the index is aligned, then the sort tables are created one at a time, thereby using small chunks of memory one at a time. However if the index is non-aligned, then the sort tables are created all at once. This drastically increases the amount of memory required for this operation.
- If you are upgrading a database with partitions to SQL Server 2012 or above, you may notice a change in the histogram for the indexes. This is because starting SQL Server 2012, statistics are created by using the default sampling instead of scanning all the rows.
- Use the TOP/MAX/MIN operators with care because for any queries using these operators, all the partitions must be evaluated. If the table is huge then such queries will perform slowly as it has to evaluate all the partitions before getting the desired result.
Over all, you need to evaluate partitioning based on the data in the table. Using partitioning just because it is a cool feature can have adverse effects in an OLTP environment. Partitioning is a right choice where you have a huge table to deal with as seen in Data warehousing environments.
You can read Pinal Dave’s other blogs here that cover more SQL topics. For a broader scope of database solutions, check out Datavail’s frequently updated Resources section.
No comments:
Post a Comment